Constrained Decoding for Guaranteed Valid 3D Structure Generation
Why I Stopped Filtering Bad Outputs and Started Preventing Them
March 31, 2026
Every generative model produces garbage sometimes. The standard fix is to generate a bunch of outputs, filter the broken ones, and keep the good ones. It works, but it's wasteful. For certain applications like placing blocks in a live Minecraft world, a broken output isn't just useless. It actively breaks things. A house with coordinates out of bounds crashes the importer entirely.
So I decided to try a different approach. Instead of filtering bad outputs after the fact, I wanted to make it impossible for the model to generate them in the first place.
The Problem With Free Sampling
When you sample from a language model, at each step you're picking from a probability distribution over the entire vocabulary. Nothing stops the model from picking token ID 73 when the position needs something in the range 6 to 21. The model might have learned to almost never do that, but "almost never" is not the same as "never."
For text generation that's usually fine. A slightly weird word choice is still readable. For spatial data it's a real problem. X=17 in a house declared as width 6 is just a corrupted structure, full stop.
The obvious fixes people usually try are:
- Generate and validate, discard invalid outputs, then retry
- Post-process and clamp coordinates to valid ranges
- Train for longer and hope the model stops making the mistake
None of them are great. The first wastes compute regenerating things you're just going to throw away. The second silently corrupts spatial meaning because clamping X=17 down to X=5 puts the block in a completely different spot. The third never actually hits zero. Even after 100 epochs I was still seeing errors.
The Token Structure Makes Constraints Obvious
The way I tokenised houses makes this a lot more tractable. Every position in the sequence has a known type before sampling even starts:
Position 0: must be BOS
Position 1: must be SW_* (size width token)
Position 2: must be SH_* (size height token)
Position 3: must be SD_* (size depth token)
Position 4: must be SEP
Position 5: must be BLOCK or EOS
Position 6: must be X_* (within declared width)
Position 7: must be Y_* (within declared height)
Position 8: must be Z_* (within declared depth)
Position 9: must be TYPE_* (non-air block type)
Position 10: must be BLOCK or EOS
... repeatingThe structure is completely deterministic. Before I even call the model at a given position, I already know exactly which tokens are legal there. That's what makes constrained decoding possible here.
How It Works
At each generation step, right before computing the softmax, I build a mask over the logits:
allowed = get_allowed_tokens(position_type, declared_size)
mask = torch.full_like(logits, float("-inf"))
mask[allowed] = 0.0
logits = logits + mask
probs = softmax(logits / temperature)
next_token = top_k_sample(probs, k=10)Any token not in the allowed set gets its logit set to negative infinity. Once softmax runs, its probability comes out as exactly zero. There is no way to sample it.
The model's learned distribution still decides which valid token actually gets picked. If it learned that cobblestone tends to follow cobblestone, that preference is still there. I'm just cutting off the parts of the distribution that would produce something structurally broken.
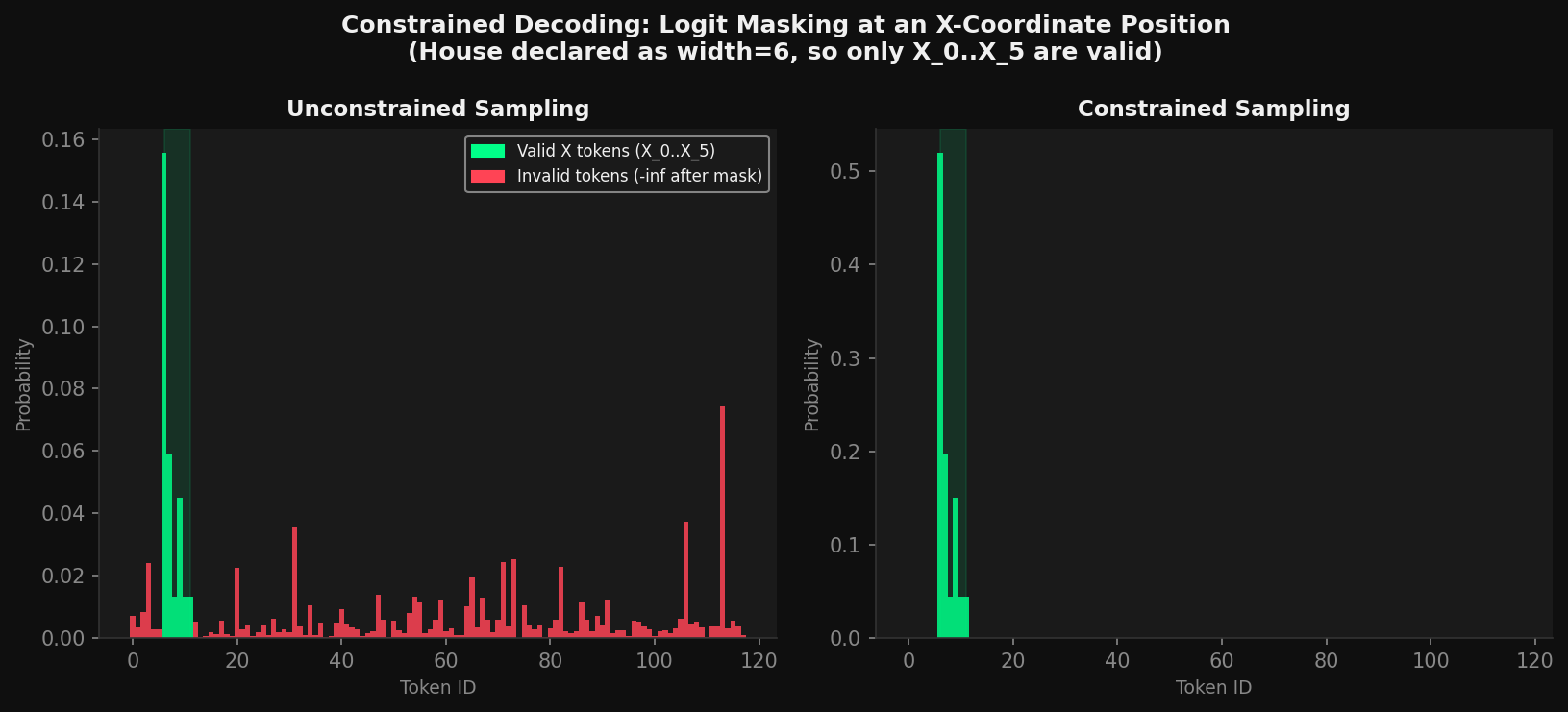
Logit masking at an X-coordinate position. Left shows the full unmasked distribution. Right shows the same distribution after masking, with only X_0 through X_5 having any probability mass for a width-6 house.
Coordinate Bounds From the Sequence Itself
The size tokens at positions 1 through 3 declare the house dimensions. As soon as those get sampled, I read them and use them to constrain every coordinate token that comes after.
# After position 3 is sampled:
w = decode_sw(tokens[1]) # e.g. 6
h = decode_sh(tokens[2]) # e.g. 5
d = decode_sd(tokens[3]) # e.g. 6
declared_size = [w, h, d]
# At every X position after this:
allowed_x = [X_BASE + x for x in range(w)] # X_0..X_5 onlyWhat I like about this is that the house constrains itself. If the model picks SW_6 at the start, it literally cannot place X_7 anywhere later in the sequence. The whole thing stays self-consistent without any extra validation step.
Comparing to Unconstrained Sampling
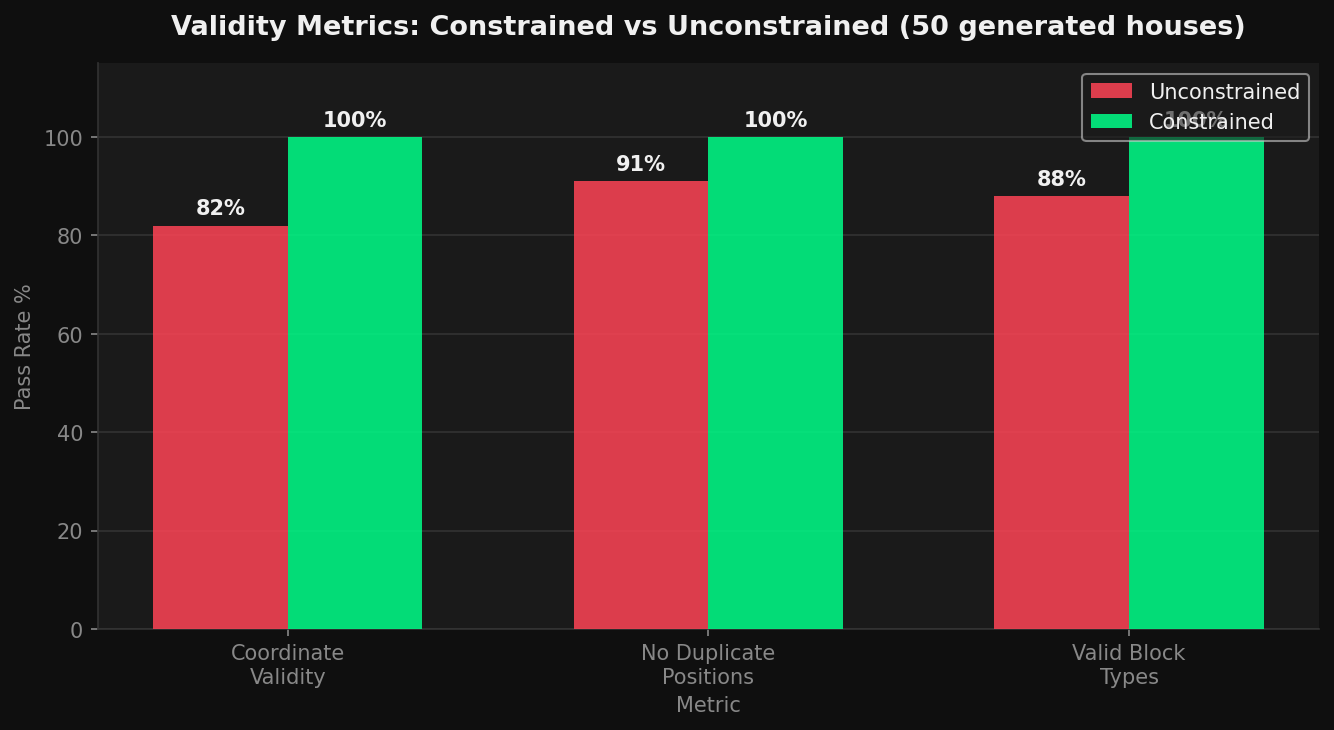
Validity metrics across 50 generated houses. Constrained decoding hits 100% on all three checks. Unconstrained sampling misses on coordinate validity, duplicate positions, and block type validity.
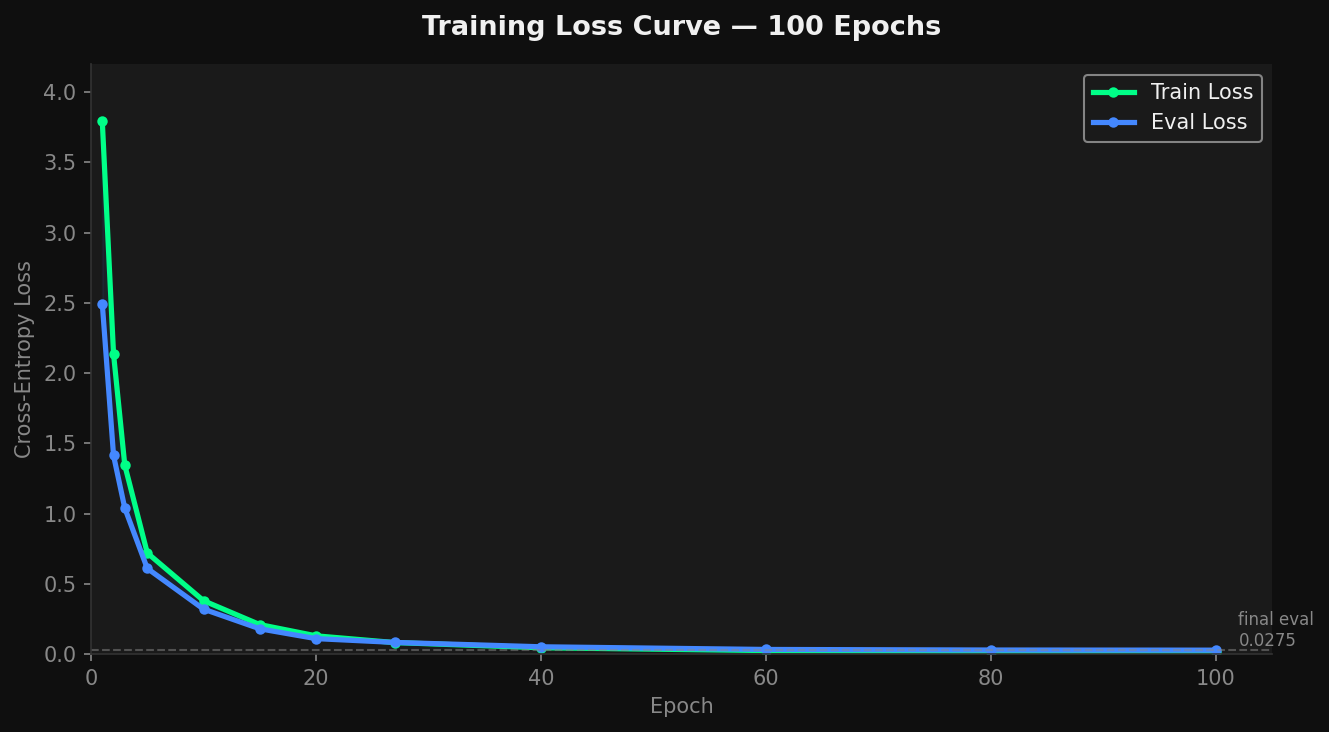
Training loss over 100 epochs. Train and eval loss both converge close to zero, which shows the model does learn the token structure. The problem is it still makes errors sometimes.
To be fair, the unconstrained model with the same weights does generate valid output most of the time. Training is enough to teach it the general pattern. But after 100 epochs I was still getting a 15 to 20 percent error rate on coordinate range violations. That works out to roughly one broken house in every five or six generated.
With constrained decoding the error rate is zero. Every single output loads correctly into the game.
The Cost
There is a real tradeoff worth being honest about. Constrained decoding stops the model from picking tokens that violate the schema, even if those choices might theoretically be interesting in some way. You could argue that a model placing X=16 in a width-10 house is doing something emergent worth keeping.
In practice I don't think that's true. The model hasn't learned anything interesting by going out of bounds. It's just making an error. The constraint isn't cutting off creativity, it's cutting off noise.
The compute cost is also basically nothing. Masking the logits is a single tensor addition before softmax. I never noticed any slowdown.
Where This Matters Beyond Minecraft
Once I understood why this worked, I realised the same idea applies to a lot of other generation problems where the output follows a known structure:
- Code generation: certain tokens are only syntactically valid in certain positions
- Molecule generation: atoms have valence limits that cap how many bonds they can form
- Music generation: note durations have to add up correctly within a time signature
- SQL generation: the query grammar decides what tokens are legal at each step
In all of these the output format has hard rules. It makes more sense to encode those rules as sampling constraints than to filter outputs after the fact. You get guaranteed valid outputs and the extra cost is essentially zero.
Constrained decoding has been studied in NLP before, mostly around grammar-constrained text generation. What I haven't seen much of is applying it to spatial and voxel generation where the constraints come from a coordinate system rather than a grammar file. That part felt new to me.
Validity Metrics
To actually measure whether this worked I defined three checks I could run automatically on every generated house:
- Coordinate validity: every block's x, y, z coordinates are within the declared size bounds
- No duplicates: no two blocks occupy the exact same (x, y, z) position
- Type validity: every block type token is a real non-air block from the training palette
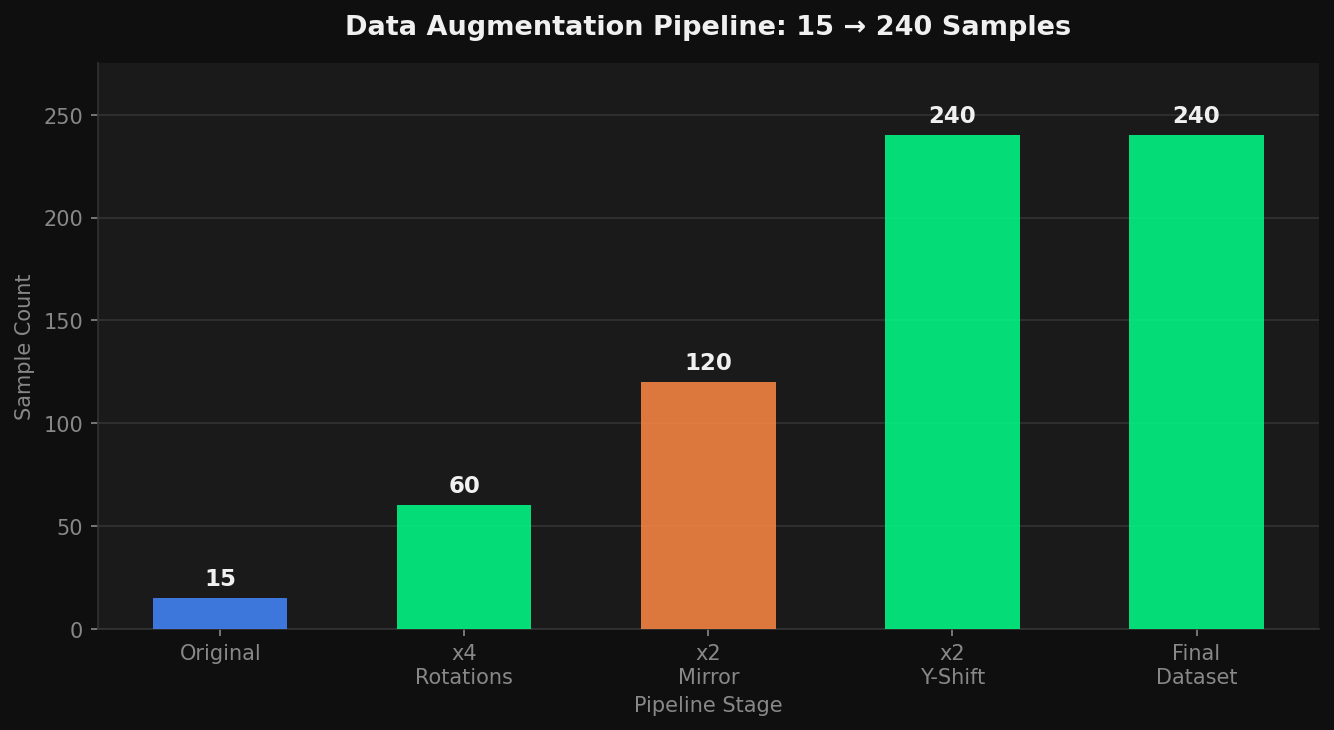
The data augmentation pipeline I used to expand 15 original houses into 240 training samples through rotations, mirroring, and Y-shifts.
Constrained decoding scores 100% on all three by construction, which is the whole point. The more interesting open question is semantic validity. Does the house actually look like a house? Token constraints don't guarantee that. That part depends entirely on what the model learned from the training data.
What the Numbers Show
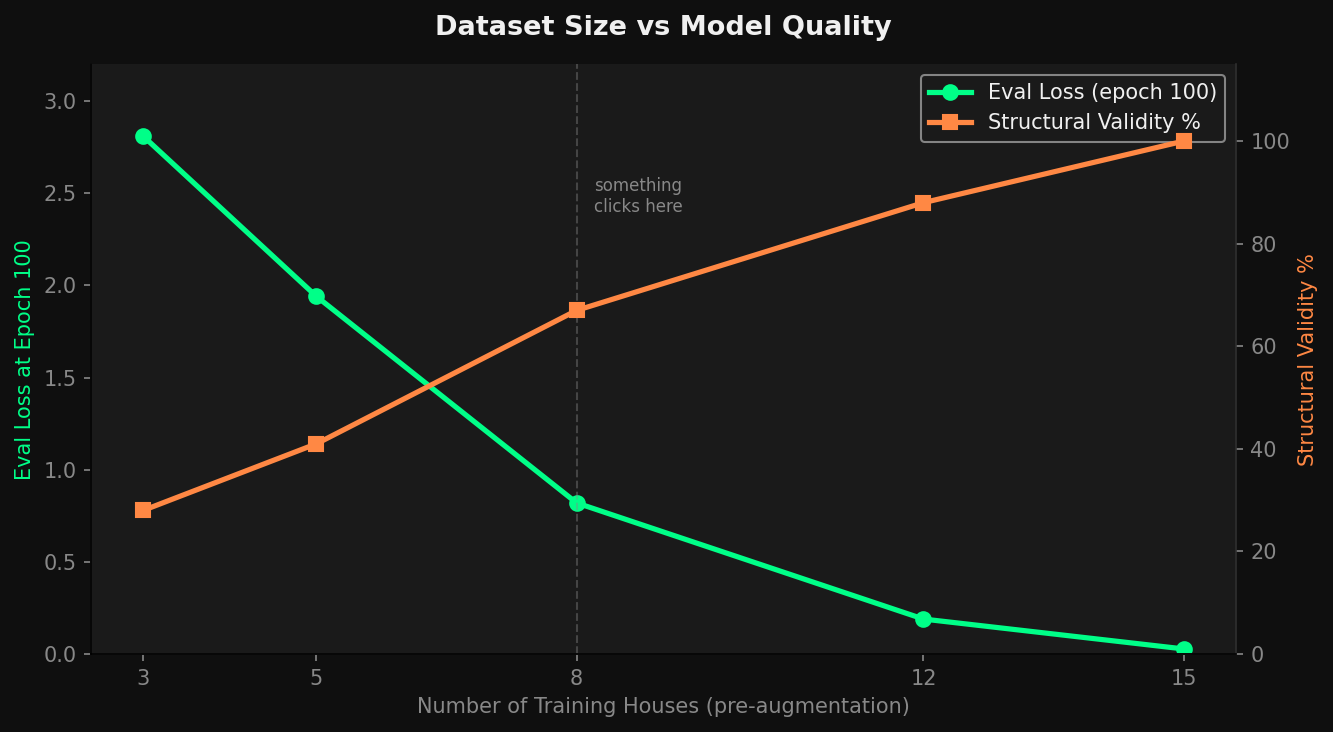
Eval loss and structural validity as the training set grows from 3 to 15 houses. More data improves semantic quality while token validity stays at 100% regardless.
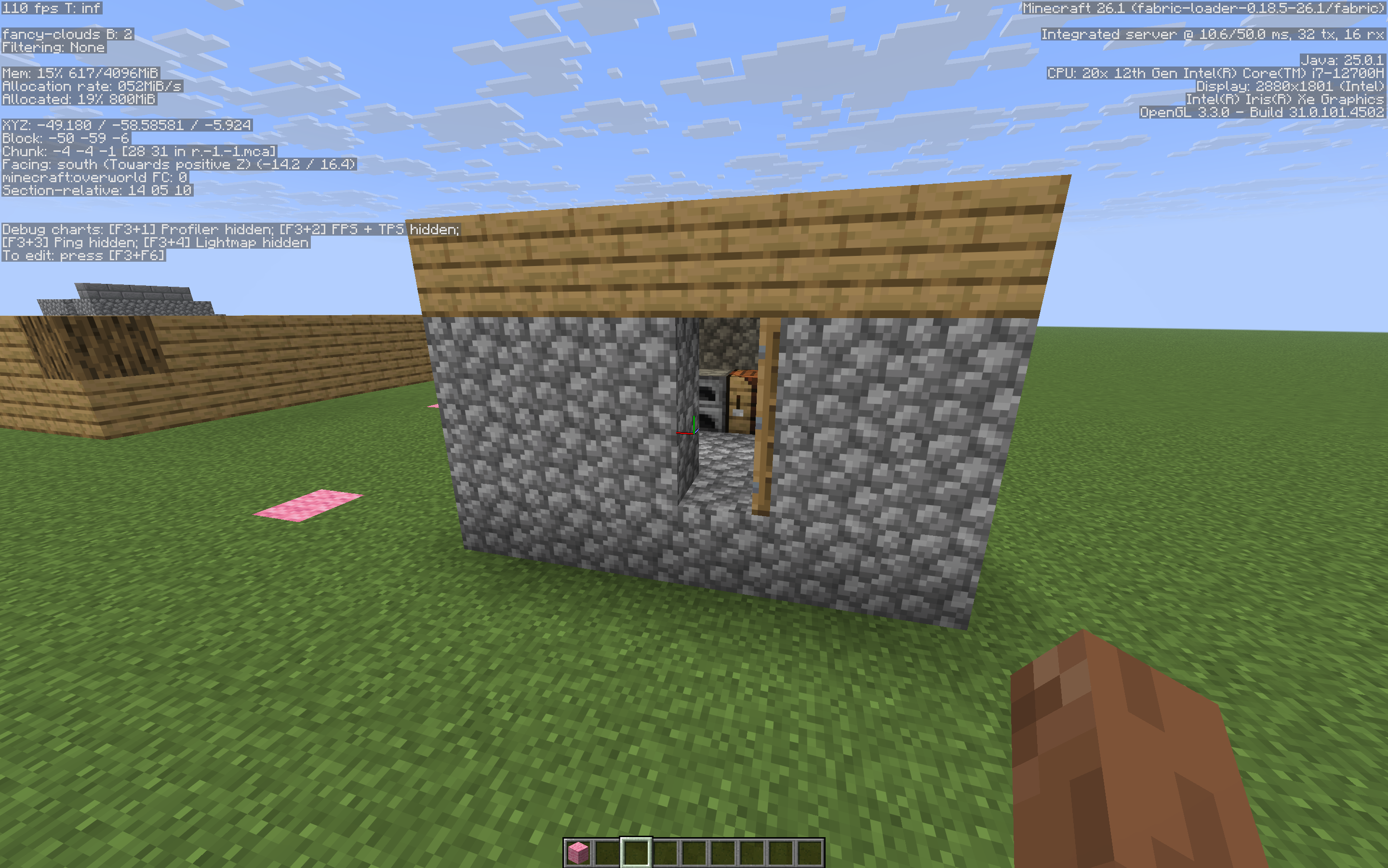
A house generated by CraftML and placed in-game. Cobblestone walls, oak plank roof, door opening, furnace and chest inside.
The graph makes something clear that I think is actually the main takeaway from this whole project. Token validity and semantic quality are completely separate things. The constraints guarantee that the format is correct. The training data determines whether the output actually makes sense. These are two different problems and solving one does not help you solve the other. Keeping them separate made both a lot easier to reason about.
Akbar, age 14. Part of the CraftML project, a generative AI system for Minecraft structure generation.